

Con la diffusione dei modelli di intelligenza artificiale generativa, sta emergendo una modalità d’uso dei contenuti online che riguarda da vicino il mondo dell’editoria: lo scraping automatizzato da parte di sistemi o servizi collegati all’AI. Il processo di web scraping è una tecnica che consente di raccogliere dati in modo automatizzato da siti web, inclusi quelli editoriali, anche quando si tratta di contenuti originali o informazioni personali. L’attività viene svolta da bot che esplorano sistematicamente le pagine online, memorizzando testi e dati per successive analisi, elaborazioni o riutilizzi, spesso senza autorizzazione né compenso.
Negli ultimi mesi, questa pratica ha assunto un nuovo significato: alimentare modelli linguistici avanzati, in grado di rispondere in tempo reale alle domande degli utenti oppure di apprendere durante la fase di addestramento da enormi quantità di dati testuali. In questo contesto, le pubblicazioni online quali articoli, analisi e approfondimenti rischiano di essere raccolti, rielaborati e restituiti al pubblico finale da chatbot, motori di ricerca evoluti o assistenti virtuali, spesso senza citazioni né ritorni economici per chi li ha prodotti.
Come funziona il web scraping?
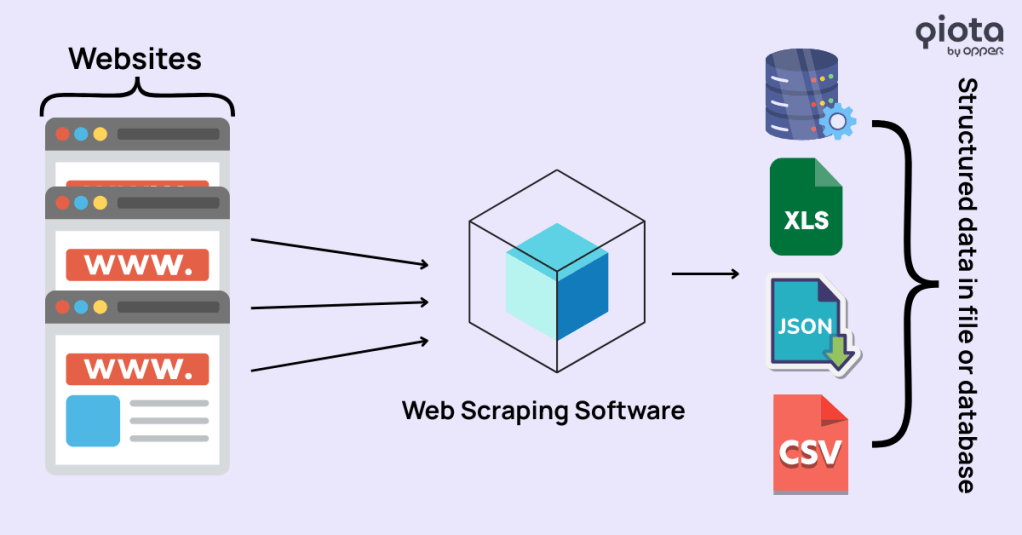
I bot di scraping accedono sistematicamente ai contenuti online, analizzano il codice HTML delle pagine (in particolare la struttura DOM), identificano le sezioni rilevanti come titoli, testi o metadati e le estraggono in modo automatizzato. I dati raccolti vengono poi convertiti in formati strutturati come CSV, JSON, file Excel o direttamente in database, rendendoli facilmente riutilizzabili per fini analitici o di addestramento.
In che modo i sistemi automatizzati interagiscono con i contenuti editoriali?
Il fenomeno riguarda trasversalmente tutti i siti che pubblicano contributi originali. Per chi li gestisce, la sfida è distinguere gli accessi provenienti da fonti riconosciute e autorizzate come i motori di ricerca da quelli automatizzati, impiegati per alimentare sistemi di intelligenza artificiale.
Le tecniche impiegate per effettuare web scraping variano e includono quelle che ignorano le direttive riportate nel file robots.txt, così come quelle che aggirano i paywall simulando il comportamento di un utente reale. Vengono anche utilizzati bot camuffati da browser comuni, oppure si accede a versioni archiviate dei contenuti tramite servizi pubblici. In questo modo, anche senza autorizzazione esplicita, è possibile che parte dei contenuti editoriali venga integrata nei sistemi AI o restituita in forma sintetica agli utenti finali.
Come difendersi: soluzioni tecniche concrete
In assenza di regole vincolanti a livello internazionale, molti editori stanno adottando misure tecnologiche per proteggere i propri contenuti dall’accesso automatizzato.
Tra le più diffuse:
- Bot Management e Web Application Firewall (WAF): soluzioni come Cloudflare, Human Security (precedentemente nota come PerimeterX), Botscorner, Imperva, e DataDome permettono di rilevare e bloccare i bot in tempo reale, distinguendo quelli legittimi, come Googlebot, da quelli mascherati. Queste tecnologie intervengono anche per facilitare l’analisi del traffico automatizzato, offrendo insight che supportano decisioni strategiche sulla gestione dei bot. Cloudflare, ad esempio, consente anche il blocco automatico dei crawler AI che non rispettano le direttive del sito.
- Tecniche anti-scraping: tra queste ci sono l’uso di honeypot (contenuti visibili solo ai bot), il fingerprinting del traffico per individuare schemi sospetti, e l’inserimento di barriere leggere, come reCAPTCHA invisibili o la richiesta di una registrazione gratuita.
- Monetizzazione dell’accesso AI: strumenti come ToIIbit offrono un controllo avanzato sull’accesso da parte dei bot AI, permettendo di regolarlo tramite licenze o API a pagamento. Anche Cloudflare ha introdotto recentemente un modello a pagamento per i bot che effettuano scraping dei dati dai siti web: chi accede tramite automazione dovrà pagare per ogni visita. Si tratta di un cambiamento significativo, che potrebbe modificare gli attuali equilibri tra accesso libero, tutela dei contenuti e uso commerciale da parte dei sistemi di intelligenza artificiale.
Secondo un’analisi condotta da ToIIbit su un ampio campione di siti editoriali, negli ultimi dodici mesi (gennaio 2024 – gennaio 2025) il numero di tentativi di bloccare i bot AI tramite il file robots.txt è quadruplicato. Questo mostra quanto gli editori siano sempre più attivi nel cercare di proteggere i propri contenuti dall’uso non autorizzato (vedi Figura 1). Tuttavia, molte aziende che sviluppano sistemi di intelligenza artificiale hanno modificato i loro sistemi per dichiarare che non sono tenute a seguire queste regole.
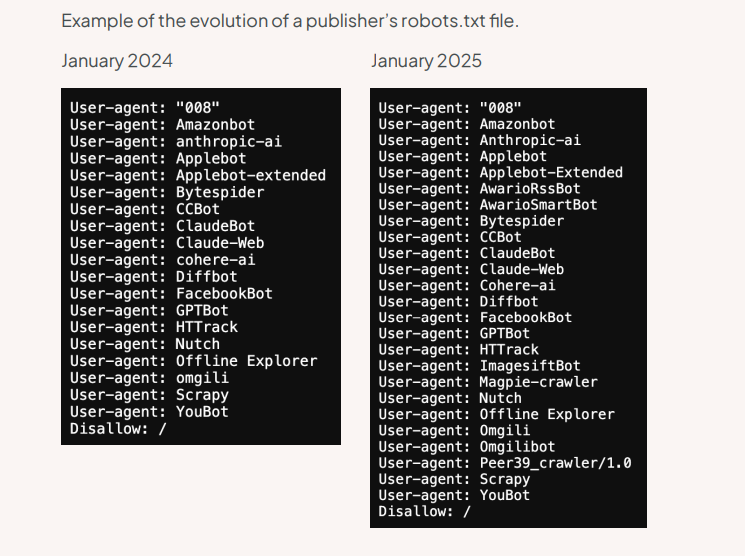
Inoltre, sono diminuite le richieste di blocco nei confronti del sistema di raccolta dati di OpenAI, probabilmente nella speranza che ChatGPT generi traffico verso i siti originali. Ma questi ritorni sono ancora molto scarsi: le visite provenienti da applicazioni basate sull’AI restano minime, sollevando dubbi sull’effettiva convenienza di lasciare libero accesso ai propri contenuti.
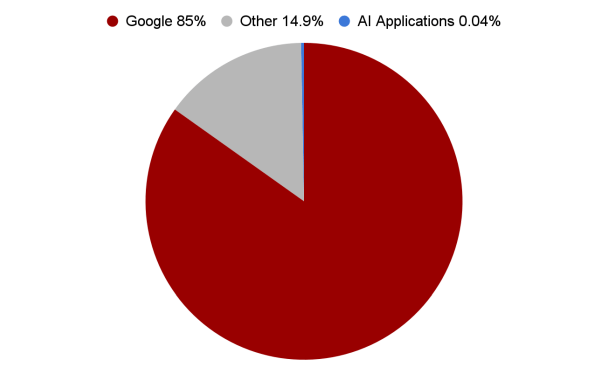
I numeri lo confermano: secondo i dati raccolti da Tollbit, solo lo 0,04% del traffico in entrata verso i siti editoriali proviene da applicazioni di intelligenza artificiale. A confronto, Google da solo genera l’85% del traffico, mentre tutte le altre fonti messe insieme rappresentano il restante 14,9%. (vedi Figura 2).
Crescita dello scraping da parte dei bot AI: i numeri più recenti
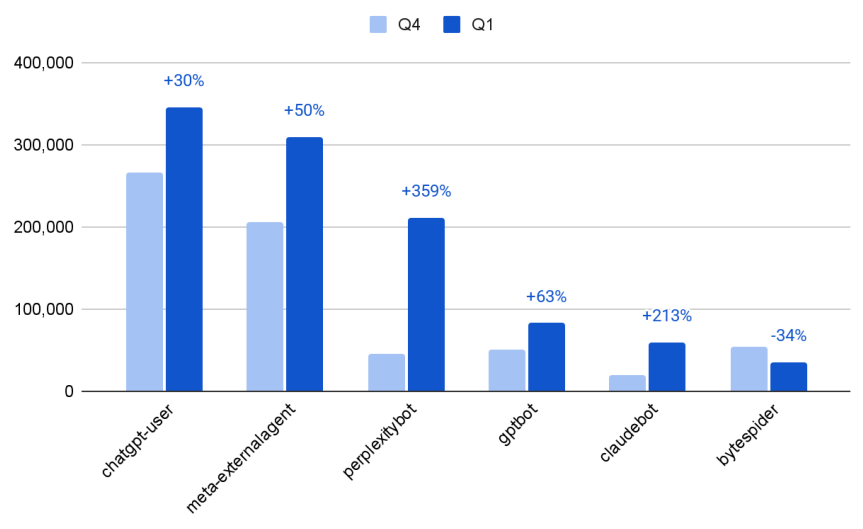
Secondo i dati più recenti, l’attività di scraping da parte dei principali bot AI è in forte crescita. Nel passaggio dal quarto trimestre del 2024 al primo trimestre del 2025, l’attività media mensile per sito da parte dei 6 bot AI più attivi è aumentata del 56%, con andamenti molto diversi tra un bot e l’altro (vedi Figura 3). In particolare, PerplexityBot, un agente ibrido di tipo RAG utilizzato da Perplexity per indicizzare contenuti web e alimentare il proprio motore AI, ha visto un incremento del +359% rispetto al trimestre precedente. Anche altri bot come ClaudeBot (+213%), GPTBot (+63%) e i bot di Meta e ChatGPT (rispettivamente +50% e +30%) mostrano crescite importanti. Bytespider è invece l’unico tra i principali a far registrare un calo (-34%).
Report consultabile su https://tollbit.com/bots/25q1/
Accorgimenti suggeriti dal Garante della Privacy
L’Autorità Garante per la protezione dei dati personali ha pubblicato a maggio 2024 una nota informativa sul web scraping e sull’intelligenza artificiale generativa, in cui suggerisce diverse misure per limitare l’utilizzo non autorizzato dei contenuti online da parte dei modelli AI generativi.
Tra gli accorgimenti proposti:
- Limitare l’accesso pubblico tramite aree riservate con registrazione, purché non eccessivamente onerosa per l’utente.
- Inserire clausole esplicite nei Termini di Servizio, che vietino lo scraping automatizzato.
- Monitorare il traffico e applicare tecniche di rate limiting per ridurre i picchi anomali.
- Contrastare i bot con CAPTCHA, modifiche periodiche al codice HTML o incorporazione di dati in elementi non testuali come immagini.
- Possibilità di indicare nel file robots.txt l’esclusione di bot noti (come GPTBot o Google-Extended), pur sapendo che si tratta solo di una richiesta non vincolante e che non tutti i bot sono tenuti a rispettarla.
Il documento completo è reperibile a questo link.
Cosa può fare oggi un editore
Un primo passo è verificare se il proprio sito è soggetto a web scraping, utilizzando strumenti come quelli citati in precedenza. Le difese tecniche possono poi essere rafforzate con WAF, bot manager, honeypot e autenticazione leggera.
Alcuni editori stanno anche chiedendo maggiore trasparenza ai provider di intelligenza artificiale sull’uso dei propri contenuti, oppure partecipano a iniziative collettive per definire standard comuni sull’accesso e la monetizzazione.
Nel frattempo, è utile monitorare l’evoluzione normativa: sia in Europa che negli Stati Uniti si discute dell’introduzione di compensi obbligatori per l’utilizzo di contenuti editoriali da parte dei modelli AI.
Perché è importante essere informati
Rimanere aggiornati su questi temi è fondamentale per prendere decisioni consapevoli, sia sul piano tecnico che strategico. Comprendere come i contenuti vengono utilizzati, quali strumenti sono disponibili e quali scenari si stanno delineando consente agli editori di tutelare meglio il proprio lavoro e di partecipare attivamente alla definizione delle regole del nuovo ecosistema digitale.
